Map Reduce#
This notebook objective is to code in Python language a wordcount application using map-reduce process. A java version is well explained on this page
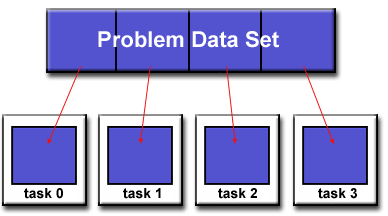
credits: https://computing.llnl.gov/tutorials/parallel_comp
map function example#
The map(func, seq) Python function applies the function func to all the elements of the sequence seq. It returns a new list with the elements changed by func
def f(x):
return x * x
rdd = [2, 6, -3, 7]
res = map(f, rdd )
res # Res is an iterator
print(*res)
from operator import mul
rdd1, rdd2 = [2, 6, -3, 7], [1, -4, 5, 3]
res = map(mul, rdd1, rdd2 ) # element wise sum of rdd1 and rdd2
print(*res)
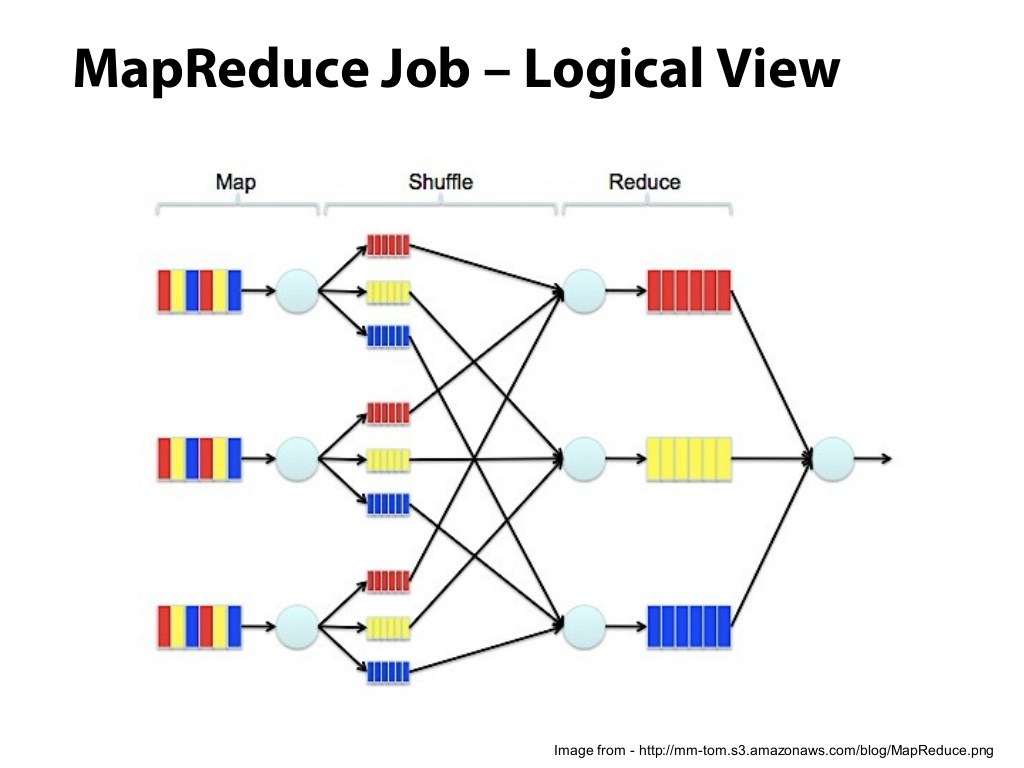
functools.reduce example#
The function reduce(func, seq) continually applies the function func() to the sequence seq and return a single value. For example, reduce(f, [1, 2, 3, 4, 5]) calculates f(f(f(f(1,2),3),4),5).
from functools import reduce
from operator import add
rdd = list(range(1,6))
reduce(add, rdd) # computes ((((1+2)+3)+4)+5)
Weighted mean and Variance#
If the generator of random variable \(X\) is discrete with probability mass function \(x_1 \mapsto p_1, x_2 \mapsto p_2, \ldots, x_n \mapsto p_n\) then
where \(\mu\) is the average value, i.e.
X = [5, 1, 2, 3, 1, 2, 5, 4]
P = [0.05, 0.05, 0.15, 0.05, 0.15, 0.2, 0.1, 0.25]
Exercise 5.1#
Write functions to compute the average value and variance using for loops
X = [5, 1, 2, 3, 1, 2, 5, 4]
P = [0.05, 0.05, 0.15, 0.05, 0.15, 0.2, 0.1, 0.25]
Exercise 5.2#
Write functions to compute the average value and variance using
mapandreduce
NB: Exercises above are just made to help to understand map-reduce process. This is a bad way to code a variance in Python. You should use Numpy instead.
Wordcount#
We will modify the wordcount application into a map-reduce process.
The map process takes text files as input and breaks it into words. The reduce process sums the counts for each word and emits a single key/value with the word and sum.
We need to split the wordcount function we wrote in notebook 04 in order to use map and reduce.
In the following exercices we will implement in Python the Java example described in Hadoop documentation.
Map - Read file and return a key/value pairs#
Exercise 5.3#
Write a function mapper with a single file name as input that returns a sorted sequence of tuples (word, 1) values.
mapper('sample.txt')
[('adipisci', 1), ('adipisci', 1), ('adipisci', 1), ('adipisci', 1), ('adipisci', 1), ('adipisci', 1), ('adipisci', 1), ('aliquam', 1), ('aliquam', 1), ('aliquam', 1), ('aliquam', 1), ('aliquam', 1), ('aliquam', 1), ('aliquam', 1), ('amet', 1), ('amet', 1), ('amet', 1)...
Partition#
Exercise 5.4#
Create a function named partitioner that stores the key/value pairs from mapper that group (word, 1) pairs into a list as:
partitioner(mapper('sample.txt'))
[('adipisci', [1, 1, 1, 1, 1, 1, 1]), ('aliquam', [1, 1, 1, 1, 1, 1, 1]), ('amet', [1, 1, 1, 1],...]
Reduce - Sums the counts and returns a single key/value (word, sum).#
Exercice 5.5#
Write the function reducer that read a tuple (word,[1,1,1,..,1]) and sum the occurrences of word to a final count, and then output the tuple (word,occurences).
reducer(('hello',[1,1,1,1,1])
('hello',5)
Process several files#
Let’s create 8 files sample[0-7].txt. Set most common words at the top of the output list.
from lorem import text
for i in range(1):
with open("sample{0:02d}.txt".format(i), "w") as f:
f.write(text())
import glob
files = sorted(glob.glob('sample0*.txt'))
files
Exercise 5.6#
Use functions implemented above to count (word, occurences) by using a for loops over files and partitioned data.
Exercise 5.7#
This time use
mapfunction to apply mapper and reducer.